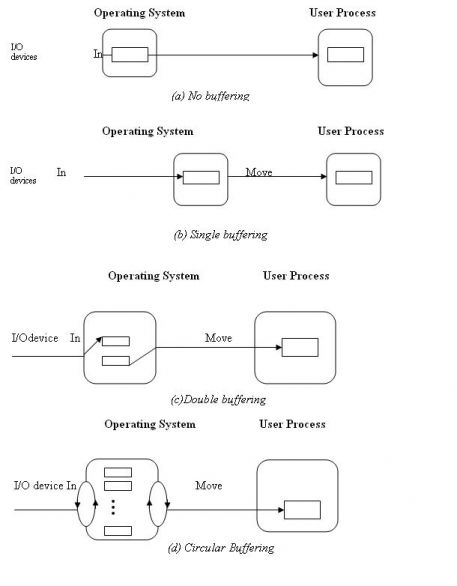
Penjadwalan
FCFS
Bentuk algoritma penjadwalan disk yang paling sederhana adalah First
Come First Served (FCFS). Sistem kerja dari algoritma ini
adalah melayani permintaan yang lebih dulu datang di queue.
Algoritma ini pada hakekatnya adil bagi permintaan M/K yang mengantri di queue karena penjadwalan ini melayani
permintaan sesuai waktu tunggunya di queue. Tetapi yang menjadi
kelemahan algoritma ini adalah bukan merupakan algoritma dengan layanan yang
tercepat. Sebagai contoh, misalnya di queue disk terdapat antrian permintaan blok I/O
di silinder

Gambar Penjadwalan FCFS
85, 35, 10, 90, 45, 80, 20, 50,
65 secara berurutan. Jika posisi head awal berada pada silinder 25, maka
pertama kali head akan bergerak dari silinder 25 ke 85,
lalu secara berurutan bergerak melayani permintaan di silinder 35, 10, 90, 45,
80, 20, 50, dan akhirnya ke silinder 65. sehingga total pergerakanhead-nya adalah 400
silinder.
Penjadwalan
SSTF
Shortest-Seek-Time-First
(SSTF) merupakan
algoritma yang melayani permintaan berdasarkan waktu pencarian yang paling
kecil dari posisi head terakhir. Sangat beralasan untuk
melayani semua permintaan yang berada dekat dengan posisi head yang sebelumnya, sebelum menggerakan head lebih jauh untuk melayani permintaan
yang lain.

Gambar Penjadwalan SSTF
Untuk contoh permintaan di queue kita, permintaan yang terdekat dari head awal (25) adalah permintaan silinder
20. maka silinder itu akan dilayani terlebih dahulu. Setelah head berada di silinder 20, maka permintaan
yang terdekat adalah silinder 10. Secara berurutan permintaan silinder
berikutnya yang dilayani adalah silinder 35, lalu 45, 50, 65, 80, 85, dan
akhirnya silinder 90. dengan menggunakan algoritma ini, maka total pergerakan head-nya
menjadi 95 silinder. Hasil yang didapat ternyata kurang dari seperempat jarak
yang dihasilkan oleh penjadwalan FCFS
Penjadwalan
SCAN dan C-SCAN
Pada algoritma SCAN, head bergerak ke silinder paling ujung dari disk.
Setelah sampai disana maka headakan berbalik arah
menuju silinder di ujung yang lainnya. Head akan melayani permintaan yang
dilaluinya selama pergerakannya ini. Algoritma ini disebut juga sebagai Elevator
Algorithm karena
sistem kerjanya yang sama seperti yang digunakan elevator di sebuah gedung
tinggi dalam melayani penggunanya. Elevator akan melayani pengguna yang akan
menuju ke atas dahulu sampai lantai tertinggi, baru setelah itu dia berbalik
arah menuju lantai terbawah sambil melayani penggunanya yang akan turun atau
sebaliknya. Jika melihat analogi yang seperti itu maka dapat dikatakan head hanya melayani permintaan yang berada
di depan arah pergerakannya. Jika ada permintaan yang berada di belakang arah
geraknya, maka permintaan tersebut harus menunggu sampai head menuju silinder di salah satu disk,
lalu berbalik arah untuk melayani permintaan tersebut.
Jika head sedang melayani permintaan silinder
25, dan arah pergerakan disk arm-nya sedang menuju
ke silinder yang terkecil, maka permintaan berikutnya yang akan dilayani secara
berurutan adalah 20 dan 10 lalu menuju ke silinder 0. Setelah sampai disini head akan berbalik arah menuju silinder
yang terbesar yaitu silinder 99. Dan dalam pergerakannya itu secara berurutan head akan melayani permintaan 35, 45, 50,
65, 80, 85, dan 90. Sehingga total pergerakan head-nya adalah 115
silinder.
Salah satu behavior yang dimiliki oleh algoritma ini
adalah, dia memiliki batas atas untuk total pergerakanhead-nya, yaitu 2 kali
jumlah silinder yang dimiliki oleh disk. Jika dilihat dari
cara kerjanya yang selalu menuju ke silinder terujung, maka dapat dilihat
kelemahan dari algoritma ini yaitu ketidakefisienannya. Mengapa head harus bergerak ke silinder 0, padahal
sudah tidak ada lagi permintaan yang lebih kecil dari silinder 10?. Bukankah
akan lebih efisien jika head langsung berbalik arah setelah
melayani permintaan silinder 10.

Penjadwalan SCAN
Kelemahan lain dari algoritma
SCAN adalah dapat menyebabkan permintaan lama menunggu pada kondisi-kondisi
tertentu. Misalkan penyebaran banyaknya permintaan yang ada di queue tidak sama. Permintaan yang berada di
depan arah pergerakan head sedikit sedangkan yang berada di ujung
satunya lebih banyak. Maka head akan melayani permintaan yang lebih
sedikit (sesuai arah pergerakannya) dan berbalik arah jika sudah sampai di
ujung disk. Jika kemudian muncul permintaan baru di
dekat head yang
terakhir, maka permintaan tersebut akan segera dilayani, sehingga permintaan
yang lebih banyak yang berada di ujung silinder yang satunya akan semakin
kelaparan. Jadi, mengapa head tidak melayani permintaan-permintaan
yang lebih banyak itu terlebih dahulu? Karena adanya kelemahan inilah maka
tercipta satu modifikasi dari algoritma SCAN, yaitu C-SCAN yang akan dibahas
berikutnya.
Algoritma C-SCAN atau Circular
SCAN merupakan
hasil modifikasi dari SCAN untuk mengurangi kemungkinan banyak permintaan yang
menunggu untuk dilayani. Perbedaan yang paling mendasar dari kedua algoritma
ini adalah pada behavior saat pergerakan head yang berbalik arah setelah sampai di
ujung disk. Pada C-SCAN, saat head sudah berada di silinder terujung disk, head akan berbalik arah dan bergerak
secepatnya menuju silinder di ujung disk yang satu lagi, tanpa melayani
permintaan yang dilalui dalam pergerakannya. Sedangkan pada SCAN akan tetap
melayani permintaan saat bergerak berbalik arah menuju ujung yang lain.
Untuk contoh permintaan seperti
SCAN, setelah head sampai di silinder 99 (permintaan
silinder 35, 45, 50, 65, 80, 85 dan 90 telah dilayani secara berurutan), maka head akan secepatnya menuju silinder 0
tanpa melayani silinder 20 dan 10. Permintaan tersebut baru dilayani ketika head sudah berbalik arah lagi setelah
mencapai silinder 0.

Penjadwalan C-SCAN
Pemilihan Algoritma Penjadwalan
Performa dari suatu sistem
biasanya tidak terlalu bergantung pada algoritma penjadwalan yang kita pakai,
karena yang paling mempengaruhi kinerja dari suatu sistem adalah jumlah dan
tipe dari pemintaan. Dan tipe permintaan juga sangat dipengaruhi oleh metoda
pengalokasian file, lokasi direktori dan
indeks blok. Karena kompleksitas ini, sebaiknya algoritma penjadwalan disk diimplementasikan sebagai modul yang
terpisah dari OS, sehingga algoritma tersebut bisa diganti dengan algoritma
lain sesuai dengan jumlah dan tipe permintaan yang ada. Namun biasanya, OS
memiliki algoritma default yang sering dipakai, yaitu SSTF.
Penerapan algoritma penjadwalan
di atas berdasarkan hanya pada jarak pencarian saja. Tapi untuk diskmodern,
selain jarak pencarian, rotation latency (waktu tunggu untuk sektor yang
diinginkan untuk berrotasi di bawah disk head) juga sangat
berpengaruh. Tetapi algoritma untuk mengurangi rotation
latency tidak dapat
diterapkan oleh OS, karena pada disk modern tidak dapat diketahui lokasi
fisik dari blok-blok logikanya. Tapi masalah rotation latency ini dapat ditangani dengan
mengimplementasikan algoritma penjadwalan disk pada hardware controller yang terdapat dalam disk
drive, sehingga kalau hanya kinerja I/O yang diperhatikan, maka
sistem operasi dapat menyerahkan algoritma penjadwalan diskpada
perangkat keras itu sendiri.
Dari seluruh algoritma yang
sudah kita bahas di atas, tidak ada algoritma yang tebaik untuk semua keadaan
yang terjadi. SSTF lebih umum dan memiliki perilaku yang lazim kita temui. SCAN
dan C-SCAN memperlihatkan kemampuan yang lebih baik bagi sistem yang
menempatkan beban pekerjaan yang berat pada disk, karena algoritma
tersebut memiliki msalah starvation yang paling sedikit. SSTF sering
dipakai sebagai algoritma dasar dalam OS.